Python基础
六个标准的数据类型
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
-
number(数字)
-
String(字符串)
- str = ‘Runoob’
- ” “ 与 ‘ ‘功能相同

-
List(列表)
- 列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
- 列表是写在方括号 [] 之间、用逗号分隔开的元素列表。

- Tuple(元组)
- tuple = ( ‘abcd’, 786 , 2.23, ‘runoob’, 70.2 )
- 元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
- 元组中的元素类型也可以不相同
- 元组与字符串类似,可以被索引且下标索引从0开始,-1 为从末尾开始的位置。
- 其实,可以把字符串看作一种特殊的元组。(字符串只能有字符,而元组可以混合结构)
- 虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
string、list 和 tuple 都属于 sequence(序列)。
-
Set(集合)
- sites = {‘Google’, ‘Taobao’, ‘Runoob’, ‘Facebook’, ‘Zhihu’, ‘Baidu’}、
- a = set(‘abracadabra’)
- 集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
- 基本功能是进行成员关系测试和删除重复元素。
- 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
- set可以进行集合运算
-
Dictionary(字典)
-
字典(dictionary)是Python中另一个非常有用的内置数据类型。
-
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
-
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
-
键(key)必须使用不可变类型。
-
在同一个字典中,键(key)必须是唯一的。
-
{ } 是用来创建一个空字典。
-
>>> dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)]) {'Runoob': 1, 'Google': 2, 'Taobao': 3} >>> dict(Runoob=1, Google=2, Taobao=3) {'Runoob': 1, 'Google': 2, 'Taobao': 3}
-
Python 推导式
-
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。
-
列表推导式
[表达式 for 变量 in 列表] [out_exp_res for out_exp in input_list] 或者 [表达式 for 变量 in 列表 if 条件] [out_exp_res for out_exp in input_list if condition]- out_exp_res:列表生成元素表达式,可以是有返回值的函数。
- for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
- if condition:条件语句,可以过滤列表中不符合条件的值。
>>> names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] >>> new_names = [name.upper()for name in names if len(name)>3] >>> print(new_names) ['ALICE', 'JERRY', 'WENDY', 'SMITH'] >>> multiples = [i for i in range(30) if i % 3 == 0] >>> print(multiples) [0, 3, 6, 9, 12, 15, 18, 21, 24, 27] -
字典推导式
-
{ key_expr: value_expr for value in collection } 或 { key_expr: value_expr for value in collection if condition } #使用字符串及其长度创建字典: listdemo = ['Google','Runoob', 'Taobao'] # 将列表中各字符串值为键,各字符串的长度为值,组成键值对 >>> newdict = {key:len(key) for key in listdemo} >>> newdict {'Google': 6, 'Runoob': 6, 'Taobao': 6} #提供三个数字,以三个数字为键,三个数字的平方为值来创建字典: >>> dic = {x: x**2 for x in (2, 4, 6)} >>> dic {2: 4, 4: 16, 6: 36} >>> type(dic) <class 'dict'> -
集合推导式
-
{ expression for item in Sequence } 或 { expression for item in Sequence if conditional } #计算数字 1,2,3 的平方数 >>> setnew = {i**2 for i in (1,2,3)} >>> setnew {1, 4, 9} #判断不是 abc 的字母并输出: >>> a = {x for x in 'abracadabra' if x not in 'abc'} >>> a {'d', 'r'} >>> type(a) <class 'set'>
-
-
元组推导式
-
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
-
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [],另外元组推导式返回的结果是一个生成器对象。
-
(expression for item in Sequence ) 或 (expression for item in Sequence if conditional ) #生成一个包含数字 1~9 的元组: >>> a = (x for x in range(1,10)) >>> a <generator object <genexpr> at 0x7faf6ee20a50> # 返回的是生成器对象 >>> tuple(a) # 使用 tuple() 函数,可以直接将生成器对象转换成元组 (1, 2, 3, 4, 5, 6, 7, 8, 9)
-
Python3迭代器与生成器
迭代器
- 迭代是Python最强大的功能之一,是访问集合元素的一种方式。
- 迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
- 迭代器只能往前不会后退。
- 迭代器有两个基本的方法:iter() 和 next()。
- iter()常用来表示第一个元素之前的位置,当需要调用第一个元素时,使用next(iter(list))
- next()则用来向前继续遍历,前指的是向右遍历,后指的是向左退回,不会向左退回
- 区别于c++的begin()和end()迭代器,c++的begin指的是第一个元素,end指的是尾后迭代器,即最后一个元素的下一个
生成器
- 在 Python 中,使用了 yield 的函数被称为生成器(generator)。
- 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
- 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
- 调用一个生成器函数,返回的是一个迭代器对象
Python3参数类型
- 必须参数
- 必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
- 调用 printme() 函数,你必须传入一个参数,不然会出现语法错误:
-
关键词参数
-
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
-
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
-
#可写函数说明 def printinfo( name, age ): "打印任何传入的字符串" print ("名字: ", name) print ("年龄: ", age) return #调用printinfo函数 printinfo( age=50, name="runoob" ) 名字: runoob 年龄: 50 ------------------------ 名字: runoob 年龄: 35
-
-
默认参数
- 调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值:
-
不定长参数
-
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。
-
一个星号 ***** 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数
-
# 可写函数说明 def printinfo( arg1, *vartuple ): "打印任何传入的参数" print ("输出: ") print (arg1) print (vartuple) # 调用printinfo 函数 printinfo( 70, 60, 50 ) 输出: 70 (60, 50)
-
-
两个星号**的参数会以字典(dict)的形式导入。
-
# 可写函数说明 def printinfo( arg1, **vardict ): "打印任何传入的参数" print ("输出: ") print (arg1) print (vardict) # 调用printinfo 函数 printinfo(1, a=2,b=3) 输出: 1 {'a': 2, 'b': 3}
-
-
匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
sum = lambda arg1, arg2: arg1 + arg2
Python模块
-
import
-
from … import …
-
from … import*
-
if __name__ == '__main__': print('程序自身在运行') else: print('我来自另一模块') $ python using_name.py 程序自身在运行 $ python >>> import using_name 我来自另一模块- 每个模块都有一个__name__属性,当其值是’main‘时,表明该模块自身在运行,否则是被引入。
- 说明:__name__ 与 __main__ 底下是双下划线, _ _ 是这样去掉中间的那个空格。
-
dir()
- 内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
-
包
- 包是一种管理 Python 模块命名空间的形式,采用”点模块名称”。
- 比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
- 就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。
- 注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
Python面向对象基础
面向对象技术
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写(覆盖):如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟”是一个(is-a)”关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
类相关
-
类定义
-
class ClassName: <statement-1> . . . <statement-N>
-
-
类的实例化 x = MyClass()
-
class Test: def prt(self): print(self) print(self.__class__) t = Test() t.prt() <__main__.Test instance at 0x100771878> __main__.Test-
类有一个名为 init() 的特殊方法(构造方法),该方法在类实例化时会自动调用
-
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的
-
-
self代表类的实例,而非类
-
类的方法
-
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。
-
#类定义 class people: #定义基本属性 name = '' age = 0 #定义私有属性,私有属性在类外部无法直接进行访问 __weight = 0 #定义构造方法 def __init__(self,n,a,w): self.name = n self.age = a self.__weight = w def speak(self): print("%s 说: 我 %d 岁。" %(self.name,self.age)) # 实例化类 p = people('runoob',10,30) p.speak() runoob 说: 我 10 岁。
-
-
继承
-
子类(派生类 DerivedClassName)会继承父类(基类 BaseClassName)的属性和方法
-
BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
-
class DerivedClassName(BaseClassName): class DerivedClassName(BaseClassName):
-
-
多继承
- class DerivedClassName(Base1, Base2, Base3):
- 需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
-
方法重写
- 如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法
- super() 函数是用于调用父类(超类)的一个方法。
-
类属性与方法
- 类的私有属性:__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
- 类的方法:在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定使用 self。
- 类的私有方法:__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
-
类的专有方法(两端加这个__ __)
- __init__ : 构造函数,在生成对象时调用
- __del__ : 析构函数,释放对象时使用
- __repr__ : 打印,转换
- __setitem__ : 按照索引赋值
- __getitem__: 按照索引获取值
- __len__: 获得长度
- __cmp__: 比较运算
- __call__: 函数调用
- __add__: 加运算
- __sub__: 减运算
- __mul__: 乘运算
- __truediv__: 除运算
- __mod__: 求余运算
- __pow__: 乘方
- 运算符重载
Python3 命名空间和作用域
命名空间
-
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
-
命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
-
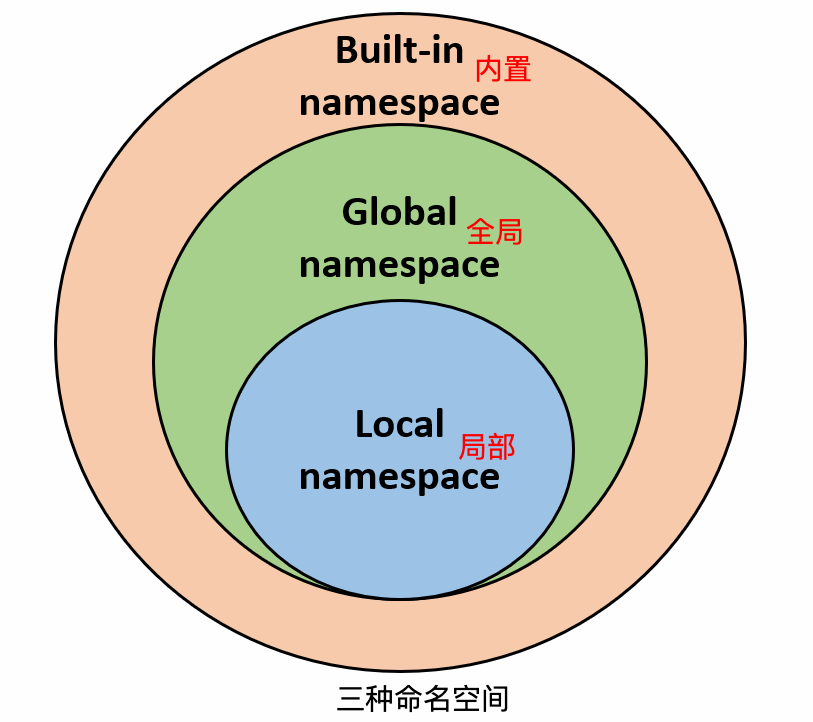
内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
-
全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
-
局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
-
命名空间查找顺序:
假设我们要使用变量 runoob,则 Python 的查找顺序为:局部的命名空间去 -> 全局命名空间 -> 内置命名空间。
作用域
-
作用域就是一个 Python 程序可以直接访问命名空间的正文区域。
-
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
-
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
-
包括4中作用域:
-
L(Local):最内层,包含局部变量,比如一个函数/方法内部。
-
E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
-
G(Global):当前脚本的最外层,比如当前模块的全局变量。
-
B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
-
规则顺序: L –> E –> G –> B。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
-

-
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问
-
全局变量和局部变量
- 定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
- 局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
global 和 nonlocal关键字
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
1
123
123
——————————————————————————————————————————————————————————
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
100
100
————————————————————————————————————————————————————————————
a = 10
def test():
global a
a = a + 1
print(a)
test()
a = 10
def test(a):
a = a + 1
print(a)
test(a)
11
Python3标准库概览
操作系统接口
- os模块提供了不少与操作系统相关联的函数。
- 建议使用 “import os” 风格而非 “from os import *“。这样可以保证随操作系统不同而有所变化的 os.open() 不会覆盖内置函数 open()。
文件通配符
- glob模块提供了一个glob函数用于从目录通配符搜索中生成文件列表:
命令行参数
- 通用工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于 sys 模块的 argv 变量。
错误输出重定向和程序终止
- sys 还有 stdin,stdout 和 stderr 属性,即使在 stdout 被重定向时,后者也可以用于显示警告和错误信息。
字符串正则匹配
- re模块为高级字符串处理提供了正则表达式工具。对于复杂的匹配和处理,正则表达式提供了简洁、优化的解决方案:
数学
- math模块为浮点运算提供了对底层C函数库的访问:
- random模块提供了生成随机数的工具。
访问 互联网
- 有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从 urls 接收的数据的 urllib.request 以及用于发送电子邮件的 smtplib
日期和时间
- datetime模块为日期和时间处理同时提供了简单和复杂的方法。
- 支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。
数据压缩
- 以下模块直接支持通用的数据打包和压缩格式:zlib,gzip,bz2,zipfile,以及 tarfile。
Python3正则表达式
re.match函数
-
从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
-
re.match(pattern,string,flags=0)参数 描述 pattern 匹配的正则表达式 string 要匹配的字符串。 flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等. - 匹配成功re.match方法返回一个匹配的对象,否则返回None。
re.search方法
-
re.search 扫描整个字符串并返回第一个成功的匹配。a
-
re.search(pattern, string, flags=0) - 匹配成功re.search方法返回一个匹配的对象,否则返回None。
re.match与re.search的区别
- re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
检索和替换
-
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
-
re.sub(pattern, repl, string, count=0, flags=0) -
pattern : 正则中的模式字符串。(必选参数)
-
repl : 替换的字符串,也可为一个函数。(必选参数)
-
string : 要被查找替换的原始字符串。(必选参数)
-
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。(可选参数)
- flags : 编译时用的匹配模式,数字形式。(可选参数)
Python装饰器
装饰器就是把@后面的装饰器函数放到被装饰函数外面,然后再赋给被装饰函数
外部函数的返回值是内部函数
不带参数的装饰器,对无返回值、无参数的函数进行装饰
def funA(fn):
#...
fn() # 执行传入的fn参数
#...
return '...'
@funA#装饰器
def funB():
#与上面完全相同
def funB():
#...
funB = funA(funB)
通过比对以上 2 段程序不难发现,使用函数装饰器 A() 去装饰另一个函数 B(),其底层执行了如下 2 步操作:
- B 作为参数传给 A() 函数;
- 将 A() 函数执行完成的返回值反馈回 B。
不带参数的装饰器,对无返回值、有参数的函数进行修饰
def funA(fn):
# 定义一个嵌套函数
def say(arc):
print("Python教程:",arc)
return say
@funA
def funB(arc):
print("funB():", a)
funB("http://c.biancheng.net/python")
#执行结果
#Python教程: http://c.biancheng.net/python
#等价
def funB(arc):
print("funB():", a)
funB = funA(funB)
funB("http://c.biancheng.net/python")
- 显然,通过 funB() 函数被装饰器 funA() 修饰,funB 就被赋值为 say。这意味着,虽然我们在程序显式调用的是 funB() 函数,但其实执行的是装饰器嵌套的 say() 函数。
多个函数被同一个装饰器修饰,函数的参数个数不相等
def funA(fn):
# 定义一个嵌套函数
def say(*args,**kwargs):
fn(*args,**kwargs)
return say
@funA
def funB(arc):
print("C语言中文网:",arc)
@funA
def other_funB(name,arc):
print(name,arc)
funB("http://c.biancheng.net")
other_funB("Python教程:","http://c.biancheng.net/python")
#运行结果为
#C语言中文网: http://c.biancheng.net
#Python教程: http://c.biancheng.net/python
嵌套的装饰器
@funA
@funB
@funC
def fun():
#...
上面程序的执行顺序是里到外,所以它等效于下面这行代码:
fun = funA( funB ( funC (fun) ) )
带参数的装饰器
def logging(level):
def outwrapper(func):
def wrapper(*args, **kwargs):
print("[{0}]: enter {1}()".format(level, func.__name__))
return func(*args, **kwargs)
return wrapper
return outwrapper
@logging(level="INFO")
def hello(a, b, c):
print(a, b, c)
hello("hello,","good","morning")
-----------------------------
>>>[INFO]: enter hello()
>>>hello, good morning
装饰器中可以传入参数,先形成一个完整的装饰器,然后再来装饰函数,当然函数如果需要传入参数也是可以的,用不定长参数符号就可以接收,例子中传入了三个参数。
python生成器
-
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的
[]改成(),就创建了一个generator>>> L = [x * x for x in range(10)] >>> L [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> g = (x * x for x in range(10)) >>> g <generator object <genexpr> at 0x1022ef630>- generator保存的是算法,每次调用
next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。 - 创建了一个generator后,基本上永远不会调用
next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
- generator保存的是算法,每次调用
-
这就是定义generator的另一种方法。如果一个函数定义中包含
yield关键字,那么这个函数就不再是一个普通函数,而是一个generator函数,调用一个generator函数将返回一个generator-
这里,最难理解的就是generator函数和普通函数的执行流程不一样。普通函数是顺序执行,遇到
return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。 -
>>> o = odd() >>> next(o) step 1 1 >>> next(o) step 2 3 >>> next(o) step 3 5 >>> next(o) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration #可以看到,odd不是普通函数,而是generator函数,在执行过程中,遇到yield就中断,下次又继续执行。执行3次yield后,已经没有yield可以执行了,所以,第#4次调用next(o)就报错。 - 请务必注意:调用generator函数会创建一个generator对象,多次调用generator函数会创建多个相互独立的generator。
-
python 迭代器
-
我们已经知道,可以直接作用于
for循环的数据类型有以下几种:- 一类是集合数据类型,如
list、tuple、dict、set、str等; - 一类是
generator,包括生成器和带yield的generator function。这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
- 一类是集合数据类型,如
-
可以使用
isinstance()判断一个对象是否是Iterable对象:-
>>> from collections.abc import Iterable >>> isinstance([], Iterable) True >>> isinstance({}, Iterable) True >>> isinstance('abc', Iterable) True >>> isinstance((x for x in range(10)), Iterable) True >>> isinstance(100, Iterable) False
-
-
生成器都是
Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。把list、dict、str等Iterable变成Iterator可以使用iter()函数:>>> isinstance(iter([]), Iterator) True >>> isinstance(iter('abc'), Iterator) True - 你可能会问,为什么
list、dict、str等数据类型不是Iterator?- 这是因为Python的
Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。 Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
- 这是因为Python的
- 凡是可作用于
for循环的对象都是Iterable类型; - 凡是可作用于
next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列; - 集合数据类型如
list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。 - Python的
for循环本质上就是通过不断调用next()函数实现的
偏函数(functools.partial)
- 简单总结
functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。 - 注意到上面的新的
int2函数,仅仅是把base参数重新设定默认值为2,但也可以在函数调用时传入其他值
面向对象编程
类和实例
-
于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的
__init__方法,在创建实例的时候,就把name,score等属性绑上去:-
class Student(object): def __init__(self, name, score): self.name = name self.score = score -
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。 -
注意到
__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。 -
有了
__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去 -
>>> bart = Student('Bart Simpson', 59) >>> bart.name 'Bart Simpson' >>> bart.score 59
-
-
数据封装
- 要定义一个方法,除了第一个参数是
self外,其他和普通函数一样。要调用一个方法,只需要在实例变量上直接调用,除了self不用传递,其他参数正常传入
- 要定义一个方法,除了第一个参数是
-
小结
- 类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;
- 方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;
- 通过在实例上调用方法,我们就直接操作了对象内部的数据,但无需知道方法内部的实现细节。
访问限制
-
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线
__,在Python中,实例的变量名如果以__开头(如果开头和结尾都是双下划线,那就是特殊变量,不是内部变量,可以被外部访问),就变成了一个私有变量(private),只有内部可以访问,外部不能访问-
这样就确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。
-
但是如果外部代码要获取name和score怎么办?可以给Student类增加
get_name和get_score这样的方法:class Student(object): ... def get_name(self): return self.__name def get_score(self): return self.__score -
如果又要允许外部代码修改score怎么办?可以再给Student类增加
set_score方法:
class Student(object): ... def set_score(self, score): self.__score = score- 你也许会问,原先那种直接通过
bart.score = 99也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数:
class Student(object): ... def set_score(self, score): if 0 <= score <= 100: self.__score = score else: raise ValueError('bad score') -
- 需要注意的是,在Python中,变量名类似
__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。 - 有些时候,你会看到以一个下划线开头的实例变量名,比如
_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。 - 双下划线开头的实例变量是不是一定不能从外部访问呢?其实也不是。不能直接访问
__name是因为Python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量 - 但是强烈建议你不要这么干,因为不同版本的Python解释器可能会把
__name改成不同的变量名。总的来说就是,Python本身没有任何机制阻止你干坏事,一切全靠自觉。
继承和多态
继承
-
在OOP程序设计中,当我们定义一个class的时候,可以从某个现有的class继承,新的class称为子类(Subclass),而被继承的class称为基类、父类或超类(Base class、Super class)。
- 比如,我们已经编写了一个名为
Animal的class,有一个run()方法可以直接打印:
class Animal(object): def run(self): print('Animal is running...')- 当我们需要编写
Dog和Cat类时,就可以直接从Animal类继承:
class Dog(Animal): pass class Cat(Animal): pass-
对于
Dog来说,Animal就是它的父类,对于Animal来说,Dog就是它的子类。Cat和Dog类似。 -
继承有什么好处?最大的好处是子类获得了父类的全部功能。由于
Animial实现了run()方法,因此,Dog和Cat作为它的子类,什么事也没干,就自动拥有了run()方法:
dog = Dog() dog.run() cat = Cat() cat.run()-
继承的第二个好处需要我们对代码做一点改进。你看到了,无论是
Dog还是Cat,它们run()的时候,显示的都是Animal is running...,符合逻辑的做法是分别显示Dog is running...和Cat is running...,因此,对Dog和Cat类改进如下:class Dog(Animal): def run(self): print('Dog is running...') class Cat(Animal): def run(self): print('Cat is running...')
- 比如,我们已经编写了一个名为
多态
-
当子类和父类都存在相同的
run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。这样,我们就获得了继承的另一个好处:多态。 -
多态的好处就是,当我们需要传入
Dog、Cat、Tortoise……时,我们只需要接收Animal类型就可以了,因为Dog、Cat、Tortoise……都是Animal类型,然后,按照Animal类型进行操作即可。由于Animal类型有run()方法,因此,传入的任意类型,只要是Animal类或者子类,就会自动调用实际类型的run()方法,这就是多态的意思:- 对于一个变量,我们只需要知道它是
Animal类型,无需确切地知道它的子类型,就可以放心地调用run()方法,而具体调用的run()方法是作用在Animal、Dog、Cat还是Tortoise对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。
- 对于一个变量,我们只需要知道它是
-
这就是著名的“开闭”原则:
-
对扩展开放:允许新增
Animal子类; -
对修改封闭:不需要修改依赖
Animal类型的run_twice()等函数。 -
继承还可以一级一级地继承下来,就好比从爷爷到爸爸、再到儿子这样的关系。而任何类,最终都可以追溯到根类object,这些继承关系看上去就像一颗倒着的树。比如如下的继承树:
-
┌───────────────┐ │ object │ └───────────────┘ │ ┌────────────┴────────────┐ │ │ ▼ ▼ ┌─────────────┐ ┌─────────────┐ │ Animal │ │ Plant │ └─────────────┘ └─────────────┘ │ │ ┌─────┴──────┐ ┌─────┴──────┐ │ │ │ │ ▼ ▼ ▼ ▼ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ Dog │ │ Cat │ │ Tree │ │ Flower │ └─────────┘ └─────────┘ └─────────┘ └─────────┘
-
静态语言 vs 动态语言
-
对于静态语言(例如Java)来说,如果需要传入
Animal类型,则传入的对象必须是Animal类型或者它的子类,否则,将无法调用run()方法。 -
对于Python这样的动态语言来说,则不一定需要传入
Animal类型。我们只需要保证传入的对象有一个run()方法就可以了:
class Timer(object):
def run(self):
print('Start...')
-
这就是动态语言的“鸭子类型”(动态语言),它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
-
Python的“file-like object“就是一种鸭子类型。对真正的文件对象,它有一个
read()方法,返回其内容。但是,许多对象,只要有read()方法,都被视为“file-like object“。许多函数接收的参数就是“file-like object“,你不一定要传入真正的文件对象,完全可以传入任何实现了read()方法的对象。
获取对象信息
type()
- 基本类型都可以用
type()判断:
>>> type(123)
<class 'int'>
>>> type('str')
<class 'str'>
>>> type(None)
<type(None) 'NoneType'>
- 如果一个变量指向函数或者类,也可以用
type()判断:
>>> type(abs)
<class 'builtin_function_or_method'>
>>> type(a)
<class '__main__.Animal'>
- 如果要判断一个对象是否是函数怎么办?可以使用
types模块中定义的常量:
>>> import types
>>> def fn():
... pass
...
>>> type(fn)==types.FunctionType
True
>>> type(abs)==types.BuiltinFunctionType
True
>>> type(lambda x: x)==types.LambdaType
True
>>> type((x for x in range(10)))==types.GeneratorType
True
isinstance()–>继承很好用
- 对于class的继承关系来说,使用
type()就很不方便。我们要判断class的类型,可以使用isinstance()函数。 - 总是优先使用isinstance()判断类型,可以将指定类型及其子类“一网打尽”。
dir()
-
如果要获得一个对象的所有属性和方法,可以使用
dir()函数,它返回一个包含字符串的list,比如,获得一个str对象的所有属性和方法 -
类似
__xxx__的属性和方法在Python中都是有特殊用途的,比如__len__方法返回长度。在Python中,如果你调用len()函数试图获取一个对象的长度,实际上,在len()函数内部,它自动去调用该对象的__len__()方法,所以,下面的代码是等价的:-
>>> len('ABC') 3 >>> 'ABC'.__len__() 3 -
我们自己写的类,如果也想用
len(myObj)的话,就自己写一个__len__()方法:>>> class MyDog(object): ... def __len__(self): ... return 100 ... >>> dog = MyDog() >>> len(dog) 100
-
实例属性和类属性
实例属性
-
由于Python是动态语言,根据类创建的实例可以任意绑定属性。
-
给实例绑定属性的方法是通过实例变量,或者通过
self变量:-
class Student(object): def __init__(self, name): self.name = name s = Student('Bob') s.score = 90
-
类属性
- 但是,如果
Student类本身需要绑定一个属性呢?可以直接在class中定义属性,这种属性是类属性,归Student类所有:
class Student(object):
name = 'Student'
- 当我们定义了一个类属性后,这个属性虽然归类所有,但类的所有实例都可以访问到。
小结
- 在编写程序的时候,千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
__slots__:规定可以绑定的实例属性
- 正常情况下,当我们定义了一个class,创建了一个class的实例后,我们可以给该实例绑定任何属性和方法,这就是动态语言的灵活性。先定义class:
class Student(object):
pass
- 然后,尝试给实例绑定一个属性:
>>> s = Student()
>>> s.name = 'Michael' # 动态给实例绑定一个属性
>>> print(s.name)
Michael
- 还可以尝试给实例绑定一个方法:
>>> def set_age(self, age): # 定义一个函数作为实例方法
... self.age = age
...
>>> from types import MethodType
>>> s.set_age = MethodType(set_age, s) # 给实例绑定一个方法
>>> s.set_age(25) # 调用实例方法
>>> s.age # 测试结果
25
- 但是,给一个实例绑定的方法,对另一个实例是不起作用的:
>>> s2 = Student() # 创建新的实例
>>> s2.set_age(25) # 尝试调用方法
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'set_age'
- 为了给所有实例都绑定方法,可以给class绑定方法:
>>> def set_score(self, score):
... self.score = score
...
>>> Student.set_score = set_score
- 给class绑定方法后,所有实例均可调用:
>>> s.set_score(100)
>>> s.score
100
>>> s2.set_score(99)
>>> s2.score
99
- 通常情况下,上面的
set_score方法可以直接定义在class中,但动态绑定允许我们在程序运行的过程中动态给class加上功能,这在静态语言中很难实现。
使用__slots__
- 但是,如果我们想要限制实例的属性怎么办?比如,只允许对Student实例添加
name和age属性。 - 为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的
__slots__变量,来限制该class实例能添加的属性:
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
- 然后,我们试试:
>>> s = Student() # 创建新的实例
>>> s.name = 'Michael' # 绑定属性'name'
>>> s.age = 25 # 绑定属性'age'
>>> s.score = 99 # 绑定属性'score'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'score'
-
由于
'score'没有被放到__slots__中,所以不能绑定score属性,试图绑定score将得到AttributeError的错误。 -
使用
__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的。除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。:
>>> class GraduateStudent(Student):
... pass
...
>>> g = GraduateStudent()
>>> g.score = 9999
@property
-
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改:
s = Student() s.score = 9999- 这显然不合逻辑。为了限制score的范围,可以通过一个
set_score()方法来设置成绩,再通过一个get_score()来获取成绩,这样,在set_score()方法里,就可以检查参数
- 这显然不合逻辑。为了限制score的范围,可以通过一个
-
对于类的方法,装饰器一样起作用。Python内置的
@property装饰器就是负责把一个方法变成属性调用的:
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
@property的实现比较复杂,我们先考察如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
>>> s = Student()
>>> s.score = 60 # OK,实际转化为s.set_score(60)
>>> s.score # OK,实际转化为s.get_score()
60
>>> s.score = 9999
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
-
注意到这个神奇的
@property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的。 -
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性:
class Student(object):
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
self._birth = value
@property
def age(self):
return 2015 - self._birth
- 上面的
birth是可读写属性,而age就是一个只读属性,因为age可以根据birth和当前时间计算出来。
要特别注意:属性的方法名不要和实例变量重名。例如,以下的代码是错误的:
class Student(object):
# 方法名称和实例变量均为birth:
@property
def birth(self):
return self.birth
- 这是因为调用
s.birth时,首先转换为方法调用,在执行return self.birth时,又视为访问self的属性,于是又转换为方法调用,造成无限递归,最终导致栈溢出报错RecursionError。
多重继承
-
继承是面向对象编程的一个重要的方式,因为通过继承,子类就可以扩展父类的功能。
- 回忆一下
Animal类层次的设计,假设我们要实现以下4种动物:- Dog - 狗狗;
- Bat - 蝙蝠;
- Parrot - 鹦鹉;
- Ostrich - 鸵鸟。
- 如果按照哺乳动物和鸟类归类,我们可以设计出这样的类的层次:
┌───────────────┐
│ Animal │
└───────────────┘
│
┌────────────┴────────────┐
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Mammal │ │ Bird │
└─────────────┘ └─────────────┘
│ │
┌─────┴──────┐ ┌─────┴──────┐
│ │ │ │
▼ ▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ Dog │ │ Bat │ │ Parrot │ │ Ostrich │
└─────────┘ └─────────┘ └─────────┘ └─────────┘
- 但是如果按照“能跑”和“能飞”来归类,我们就应该设计出这样的类的层次:
┌───────────────┐
│ Animal │
└───────────────┘
│
┌────────────┴────────────┐
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Runnable │ │ Flyable │
└─────────────┘ └─────────────┘
│ │
┌─────┴──────┐ ┌─────┴──────┐
│ │ │ │
▼ ▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ Dog │ │ Ostrich │ │ Parrot │ │ Bat │
└─────────┘ └─────────┘ └─────────┘ └─────────┘
- 如果要把上面的两种分类都包含进来,我们就得设计更多的层次:
- 哺乳类:能跑的哺乳类,能飞的哺乳类;
- 鸟类:能跑的鸟类,能飞的鸟类。
- 这么一来,类的层次就复杂了:
┌───────────────┐
│ Animal │
└───────────────┘
│
┌────────────┴────────────┐
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Mammal │ │ Bird │
└─────────────┘ └─────────────┘
│ │
┌─────┴──────┐ ┌─────┴──────┐
│ │ │ │
▼ ▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ MRun │ │ MFly │ │ BRun │ │ BFly │
└─────────┘ └─────────┘ └─────────┘ └─────────┘
│ │ │ │
│ │ │ │
▼ ▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ Dog │ │ Bat │ │ Ostrich │ │ Parrot │
└─────────┘ └─────────┘ └─────────┘ └─────────┘
-
如果要再增加“宠物类”和“非宠物类”,这么搞下去,类的数量会呈指数增长,很明显这样设计是不行的。
-
正确的做法是采用多重继承。首先,主要的类层次仍按照哺乳类和鸟类设计:
class Animal(object):
pass
# 大类:
class Mammal(Animal):
pass
class Bird(Animal):
pass
# 各种动物:
class Dog(Mammal):
pass
class Bat(Mammal):
pass
class Parrot(Bird):
pass
class Ostrich(Bird):
pass
- 现在,我们要给动物再加上
Runnable和Flyable的功能,只需要先定义好Runnable和Flyable的类:
class Runnable(object):
def run(self):
print('Running...')
class Flyable(object):
def fly(self):
print('Flying...')
- 对于需要
Runnable功能的动物,就多继承一个Runnable,例如Dog:
class Dog(Mammal, Runnable):
pass
- 对于需要
Flyable功能的动物,就多继承一个Flyable,例如Bat:
class Bat(Mammal, Flyable):
pass
- 通过多重继承,一个子类就可以同时获得多个父类的所有功能。
MixIn
-
在设计类的继承关系时,通常,主线都是单一继承下来的,例如,
Ostrich继承自Bird。但是,如果需要“混入”额外的功能,通过多重继承就可以实现,比如,让Ostrich除了继承自Bird外,再同时继承Runnable。这种设计通常称之为MixIn。 -
为了更好地看出继承关系,我们把
Runnable和Flyable改为RunnableMixIn和FlyableMixIn。类似的,你还可以定义出肉食动物CarnivorousMixIn和植食动物HerbivoresMixIn,让某个动物同时拥有好几个MixIn:
class Dog(Mammal, RunnableMixIn, CarnivorousMixIn):
pass
-
MixIn的目的就是给一个类增加多个功能,这样,在设计类的时候,我们优先考虑通过多重继承来组合多个MixIn的功能,而不是设计多层次的复杂的继承关系。
-
Python自带的很多库也使用了MixIn。举个例子,Python自带了
TCPServer和UDPServer这两类网络服务,而要同时服务多个用户就必须使用多进程或多线程模型,这两种模型由ForkingMixIn和ThreadingMixIn提供。通过组合,我们就可以创造出合适的服务来。 -
比如,编写一个多进程模式的TCP服务,定义如下:
class MyTCPServer(TCPServer, ForkingMixIn):
pass
- 编写一个多线程模式的UDP服务,定义如下:
class MyUDPServer(UDPServer, ThreadingMixIn):
pass
- 如果你打算搞一个更先进的协程模型,可以编写一个
CoroutineMixIn:
class MyTCPServer(TCPServer, CoroutineMixIn):
pass
- 这样一来,我们不需要复杂而庞大的继承链,只要选择组合不同的类的功能,就可以快速构造出所需的子类。
定制类
- 看到类似
__slots__这种形如__xxx__的变量或者函数名就要注意,这些在Python中是有特殊用途的。
__slots__我们已经知道怎么用了,__len__()方法我们也知道是为了能让class作用于len()函数。
除此之外,Python的class中还有许多这样有特殊用途的函数,可以帮助我们定制类。
__str__
我们先定义一个Student类,打印一个实例:
>>> class Student(object):
... def __init__(self, name):
... self.name = name
...
>>> print(Student('Michael'))
<__main__.Student object at 0x109afb190>
-
打印出一堆
<__main__.Student object at 0x109afb190>,不好看。 -
怎么才能打印得好看呢?只需要定义好
__str__()方法,返回一个好看的字符串就可以了:
>>> class Student(object):
... def __init__(self, name):
... self.name = name
... def __str__(self):
... return 'Student object (name: %s)' % self.name
...
>>> print(Student('Michael'))
Student object (name: Michael)
-
这样打印出来的实例,不但好看,而且容易看出实例内部重要的数据。
-
但是细心的朋友会发现直接敲变量不用
print,打印出来的实例还是不好看:
>>> s = Student('Michael')
>>> s
<__main__.Student object at 0x109afb310>
-
这是因为直接显示变量调用的不是
__str__(),而是__repr__(),两者的区别是__str__()返回用户看到的字符串,而__repr__()返回程序开发者看到的字符串,也就是说,__repr__()是为调试服务的。 -
解决办法是再定义一个
__repr__()。但是通常__str__()和__repr__()代码都是一样的,所以,有个偷懒的写法:
class Student(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Student object (name=%s)' % self.name
__repr__ = __str__
__iter__
-
如果一个类想被用于
for ... in循环,类似list或tuple那样,就必须实现一个__iter__()方法,该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的__next__()方法拿到循环的下一个值,直到遇到StopIteration错误时退出循环。 -
我们以斐波那契数列为例,写一个Fib类,可以作用于for循环:
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值
- 现在,试试把Fib实例作用于for循环:
>>> for n in Fib():
... print(n)
...
1
1
2
3
5
...
46368
75025
__getitem__
- Fib实例虽然能作用于for循环,看起来和list有点像,但是,把它当成list来使用还是不行,比如,取第5个元素:
>>> Fib()[5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'Fib' object does not support indexing
- 要表现得像list那样按照下标取出元素,需要实现
__getitem__()方法:
class Fib(object):
def __getitem__(self, n):
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
- 现在,就可以按下标访问数列的任意一项了:
>>> f = Fib()
>>> f[0]
1
>>> f[1]
1
>>> f[2]
2
>>> f[3]
3
>>> f[10]
89
>>> f[100]
573147844013817084101
- 但是list有个神奇的切片方法:
>>> list(range(100))[5:10]
[5, 6, 7, 8, 9]
- 对于Fib却报错。原因是
__getitem__()传入的参数可能是一个int,也可能是一个切片对象slice,所以要做判断:
class Fib(object):
def __getitem__(self, n):
if isinstance(n, int): # n是索引
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
if isinstance(n, slice): # n是切片
start = n.start
stop = n.stop
if start is None:
start = 0
a, b = 1, 1
L = []
for x in range(stop):
if x >= start:
L.append(a)
a, b = b, a + b
return L
- 现在试试Fib的切片:
>>> f = Fib()
>>> f[0:5]
[1, 1, 2, 3, 5]
>>> f[:10]
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
- 但是没有对step参数作处理:
>>> f[:10:2]
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
-
也没有对负数作处理,所以,要正确实现一个
__getitem__()还是有很多工作要做的。 -
此外,如果把对象看成
dict,__getitem__()的参数也可能是一个可以作key的object,例如str。 -
与之对应的是
__setitem__()方法,把对象视作list或dict来对集合赋值。最后,还有一个__delitem__()方法,用于删除某个元素。 -
总之,通过上面的方法,我们自己定义的类表现得和Python自带的list、tuple、dict没什么区别,这完全归功于动态语言的“鸭子类型”,不需要强制继承某个接口。
__getattr__
- 正常情况下,当我们调用类的方法或属性时,如果不存在,就会报错。比如定义
Student类:
class Student(object):
def __init__(self):
self.name = 'Michael'
- 调用
name属性,没问题,但是,调用不存在的score属性,就有问题了:
>>> s = Student()
>>> print(s.name)
Michael
>>> print(s.score)
Traceback (most recent call last):
...
AttributeError: 'Student' object has no attribute 'score'
-
错误信息很清楚地告诉我们,没有找到
score这个attribute。 -
要避免这个错误,除了可以加上一个
score属性外,Python还有另一个机制,那就是写一个__getattr__()方法,动态返回一个属性。修改如下:
class Student(object):
def __init__(self):
self.name = 'Michael'
def __getattr__(self, attr):
if attr=='score':
return 99
- 当调用不存在的属性时,比如
score,Python解释器会试图调用__getattr__(self, 'score')来尝试获得属性,这样,我们就有机会返回score的值:
>>> s = Student()
>>> s.name
'Michael'
>>> s.score
99
- 返回函数也是完全可以的:
class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25
- 只是调用方式要变为:
>>> s.age()
25
-
注意,只有在没有找到属性的情况下,才调用
__getattr__,已有的属性,比如name,不会在__getattr__中查找。 -
此外,注意到任意调用如
s.abc都会返回None,这是因为我们定义的__getattr__默认返回就是None。要让class只响应特定的几个属性,我们就要按照约定,抛出AttributeError的错误:
class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25
raise AttributeError('\'Student\' object has no attribute \'%s\'' % attr)
-
这实际上可以把一个类的所有属性和方法调用全部动态化处理了,不需要任何特殊手段。
-
这种完全动态调用的特性有什么实际作用呢?作用就是,可以针对完全动态的情况作调用。
-
举个例子:
- 现在很多网站都搞REST API,比如新浪微博、豆瓣啥的,调用API的URL类似:
- http://api.server/user/friends
- http://api.server/user/timeline/list
-
如果要写SDK,给每个URL对应的API都写一个方法,那得累死,而且,API一旦改动,SDK也要改。
- 利用完全动态的
__getattr__,我们可以写出一个链式调用:
class Chain(object):
def __init__(self, path=''):
self._path = path
def __getattr__(self, path):
return Chain('%s/%s' % (self._path, path))
def __str__(self):
return self._path
__repr__ = __str__
试试:
>>> Chain().status.user.timeline.list
'/status/user/timeline/list'
这样,无论API怎么变,SDK都可以根据URL实现完全动态的调用,而且,不随API的增加而改变!
还有些REST API会把参数放到URL中,比如GitHub的API:
GET /users/:user/repos
调用时,需要把:user替换为实际用户名。如果我们能写出这样的链式调用:
Chain().users('michael').repos
就可以非常方便地调用API了。有兴趣的童鞋可以试试写出来。
__call__
-
一个对象实例可以有自己的属性和方法,当我们调用实例方法时,我们用
instance.method()来调用。能不能直接在实例本身上调用呢?在Python中,答案是肯定的。 -
任何类,只需要定义一个
__call__()方法,就可以直接对实例进行调用。请看示例:
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)
调用方式如下:
>>> s = Student('Michael')
>>> s() # self参数不要传入
My name is Michael.
-
__call__()还可以定义参数。对实例进行直接调用就好比对一个函数进行调用一样,所以你完全可以把对象看成函数,把函数看成对象,因为这两者之间本来就没啥根本的区别。 -
如果你把对象看成函数,那么函数本身其实也可以在运行期动态创建出来,因为类的实例都是运行期创建出来的,这么一来,我们就模糊了对象和函数的界限。
-
那么,怎么判断一个变量是对象还是函数呢?其实,更多的时候,我们需要判断一个对象是否能被调用,能被调用的对象就是一个
Callable对象,比如函数和我们上面定义的带有__call__()的类实例:
>>> callable(Student())
True
>>> callable(max)
True
>>> callable([1, 2, 3])
False
>>> callable(None)
False
>>> callable('str')
False
- 通过
callable()函数,我们就可以判断一个对象是否是“可调用”对象。
小结
Python的class允许定义许多定制方法,可以让我们非常方便地生成特定的类。
本节介绍的是最常用的几个定制方法,还有很多可定制的方法,请参考Python的官方文档。
使用枚举类
- 当我们需要定义常量时,一个办法是用大写变量通过整数来定义,例如月份:
JAN = 1
FEB = 2
MAR = 3
...
NOV = 11
DEC = 12
-
好处是简单,缺点是类型是
int,并且仍然是变量。 -
更好的方法是为这样的枚举类型定义一个class类型,然后,每个常量都是class的一个唯一实例。Python提供了
Enum类来实现这个功能:
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
- 这样我们就获得了
Month类型的枚举类,可以直接使用Month.Jan来引用一个常量,或者枚举它的所有成员:
for name, member in Month.__members__.items():
print(name, '=>', member, ',', member.value)
-
value属性则是自动赋给成员的int常量,默认从1开始计数。 -
如果需要更精确地控制枚举类型,可以从
Enum派生出自定义类:
from enum import Enum, unique
@unique
class Weekday(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
-
@unique装饰器可以帮助我们检查保证没有重复值。 -
访问这些枚举类型可以有若干种方法:
>>> day1 = Weekday.Mon
>>> print(day1)
Weekday.Mon
>>> print(Weekday.Tue)
Weekday.Tue
>>> print(Weekday['Tue'])
Weekday.Tue
>>> print(Weekday.Tue.value)
2
>>> print(day1 == Weekday.Mon)
True
>>> print(day1 == Weekday.Tue)
False
>>> print(Weekday(1))
Weekday.Mon
>>> print(day1 == Weekday(1))
True
>>> Weekday(7)
Traceback (most recent call last):
...
ValueError: 7 is not a valid Weekday
>>> for name, member in Weekday.__members__.items():
... print(name, '=>', member)
...
Sun => Weekday.Sun
Mon => Weekday.Mon
Tue => Weekday.Tue
Wed => Weekday.Wed
Thu => Weekday.Thu
Fri => Weekday.Fri
Sat => Weekday.Sat
- 可见,既可以用成员名称引用枚举常量,又可以直接根据value的值获得枚举常量。
进程和线程
多进程
-
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
-
Unix/Linux操作系统提供了一个
fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。 -
子进程永远返回
0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。 -
Python的
os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
- 运行结果如下:
Process (876) start...
I (876) just created a child process (877).
I am child process (877) and my parent is 876.
-
由于Windows没有
fork调用,上面的代码在Windows上无法运行。而Mac系统是基于BSD(Unix的一种)内核,所以,在Mac下运行是没有问题的,推荐大家用Mac学Python! -
有了
fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
multiprocessing
如果你打算编写多进程的服务程序,Unix/Linux无疑是正确的选择。由于Windows没有fork调用,难道在Windows上无法用Python编写多进程的程序?
由于Python是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
执行结果如下:
Parent process 928.
Child process will start.
Run child process test (929)...
Process end.
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
- 进程同步(join):
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
执行结果如下:
Parent process 669.
Waiting for all subprocesses done...
Run task 0 (671)...
Run task 1 (672)...
Run task 2 (673)...
Run task 3 (674)...
Task 2 runs 0.14 seconds.
Run task 4 (673)...
Task 1 runs 0.27 seconds.
Task 3 runs 0.86 seconds.
Task 0 runs 1.41 seconds.
Task 4 runs 1.91 seconds.
All subprocesses done.
代码解读:
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
p = Pool(5)
就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
子进程
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
下面的例子演示了如何在Python代码中运行命令nslookup www.python.org,这和命令行直接运行的效果是一样的:
import subprocess
print('$ nslookup www.python.org')
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)
运行结果:
$ nslookup www.python.org
Server: 192.168.19.4
Address: 192.168.19.4#53
Non-authoritative answer:
www.python.org canonical name = python.map.fastly.net.
Name: python.map.fastly.net
Address: 199.27.79.223
Exit code: 0
如果子进程还需要输入,则可以通过communicate()方法输入:
import subprocess
print('$ nslookup')
p = subprocess.Popen(['nslookup'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, err = p.communicate(b'set q=mx\npython.org\nexit\n')
print(output.decode('utf-8'))
print('Exit code:', p.returncode)
上面的代码相当于在命令行执行命令nslookup,然后手动输入:
set q=mx
python.org
exit
运行结果如下:
$ nslookup
Server: 192.168.19.4
Address: 192.168.19.4#53
Non-authoritative answer:
python.org mail exchanger = 50 mail.python.org.
Authoritative answers can be found from:
mail.python.org internet address = 82.94.164.166
mail.python.org has AAAA address 2001:888:2000:d::a6
Exit code: 0
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
运行结果如下:
Process to write: 50563
Put A to queue...
Process to read: 50564
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.
在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所以,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
小结
在Unix/Linux下,可以使用fork()调用实现多进程。
要实现跨平台的多进程,可以使用multiprocessing模块。
进程间通信是通过Queue、Pipes等实现的。
多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
我们前面提到了进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
import time, threading
# 新线程执行的代码:
def loop():
print('thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('thread %s ended.' % threading.current_thread().name)
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop, name='LoopThread')
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)
执行结果如下:
thread MainThread is running...
thread LoopThread is running...
thread LoopThread >>> 1
thread LoopThread >>> 2
thread LoopThread >>> 3
thread LoopThread >>> 4
thread LoopThread >>> 5
thread LoopThread ended.
thread MainThread ended.
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
Lock(进程互斥)
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
多核CPU
如果你不幸拥有一个多核CPU,你肯定在想,多核应该可以同时执行多个线程。
如果写一个死循环的话,会出现什么情况呢?
打开Mac OS X的Activity Monitor,或者Windows的Task Manager,都可以监控某个进程的CPU使用率。
我们可以监控到一个死循环线程会100%占用一个CPU。
如果有两个死循环线程,在多核CPU中,可以监控到会占用200%的CPU,也就是占用两个CPU核心。
要想把N核CPU的核心全部跑满,就必须启动N个死循环线程。
试试用Python写个死循环:
import threading, multiprocessing
def loop():
x = 0
while True:
x = x ^ 1
for i in range(multiprocessing.cpu_count()):
t = threading.Thread(target=loop)
t.start()
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有102%,也就是仅使用了一核。
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
小结
多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并发在Python中就是一个美丽的梦。
ThreadLocal
ThreadLocal应运而生,不用查找dict,ThreadLocal帮你自动做这件事:
import threading
# 创建全局ThreadLocal对象:
local_school = threading.local()
def process_student():
# 获取当前线程关联的student:
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(name):
# 绑定ThreadLocal的student:
local_school.student = name
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
执行结果:
Hello, Alice (in Thread-A)
Hello, Bob (in Thread-B)
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
小结
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。
多线程&多进程
我们介绍了多进程和多线程,这是实现多任务最常用的两种方式。现在,我们来讨论一下这两种方式的优缺点。
首先,要实现多任务,通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker。
如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker。
如果用多线程实现Master-Worker,主线程就是Master,其他线程就是Worker。
多进程模式最大的优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程。(当然主进程挂了所有进程就全挂了,但是Master进程只负责分配任务,挂掉的概率低)著名的Apache最早就是采用多进程模式。
多进程模式的缺点是创建进程的代价大,在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。
多线程模式通常比多进程快一点,但是也快不到哪去,而且,多线程模式致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。在Windows上,如果一个线程执行的代码出了问题,你经常可以看到这样的提示:“该程序执行了非法操作,即将关闭”,其实往往是某个线程出了问题,但是操作系统会强制结束整个进程。
在Windows下,多线程的效率比多进程要高,所以微软的IIS服务器默认采用多线程模式。由于多线程存在稳定性的问题,IIS的稳定性就不如Apache。为了缓解这个问题,IIS和Apache现在又有多进程+多线程的混合模式,真是把问题越搞越复杂。
线程切换
无论是多进程还是多线程,只要数量一多,效率肯定上不去,为什么呢?
我们打个比方,假设你不幸正在准备中考,每天晚上需要做语文、数学、英语、物理、化学这5科的作业,每项作业耗时1小时。
如果你先花1小时做语文作业,做完了,再花1小时做数学作业,这样,依次全部做完,一共花5小时,这种方式称为单任务模型,或者批处理任务模型。
假设你打算切换到多任务模型,可以先做1分钟语文,再切换到数学作业,做1分钟,再切换到英语,以此类推,只要切换速度足够快,这种方式就和单核CPU执行多任务是一样的了,以幼儿园小朋友的眼光来看,你就正在同时写5科作业。
但是,切换作业是有代价的,比如从语文切到数学,要先收拾桌子上的语文书本、钢笔(这叫保存现场),然后,打开数学课本、找出圆规直尺(这叫准备新环境),才能开始做数学作业。操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。
所以,多任务一旦多到一个限度,就会消耗掉系统所有的资源,结果效率急剧下降,所有任务都做不好。
计算密集型 vs. IO密集型
是否采用多任务的第二个考虑是任务的类型。我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
异步IO
考虑到CPU和IO之间巨大的速度差异,一个任务在执行的过程中大部分时间都在等待IO操作,单进程单线程模型会导致别的任务无法并行执行,因此,我们才需要多进程模型或者多线程模型来支持多任务并发执行。
现代操作系统对IO操作已经做了巨大的改进,最大的特点就是支持异步IO。如果充分利用操作系统提供的异步IO支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型,Nginx就是支持异步IO的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。由于系统总的进程数量十分有限,因此操作系统调度非常高效。用异步IO编程模型来实现多任务是一个主要的趋势。
对应到Python语言,单线程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。我们会在后面讨论如何编写协程。
常用内建模块
datetime
- datetime是Python处理日期和时间的标准库。
获取当前日期和时间
我们先看如何获取当前日期和时间:
>>> from datetime import datetime
>>> now = datetime.now() # 获取当前datetime
>>> print(now)
2015-05-18 16:28:07.198690
>>> print(type(now))
<class 'datetime.datetime'>
注意到datetime是模块,datetime模块还包含一个datetime类,通过from datetime import datetime导入的才是datetime这个类。
如果仅导入import datetime,则必须引用全名datetime.datetime。
datetime.now()返回当前日期和时间,其类型是datetime。
获取指定日期和时间
要指定某个日期和时间,我们直接用参数构造一个datetime:
>>> from datetime import datetime
>>> dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
>>> print(dt)
2015-04-19 12:20:00
datetime转换为timestamp
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。
你可以认为:
timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00
对应的北京时间是:
timestamp = 0 = 1970-1-1 08:00:00 UTC+8:00
可见timestamp的值与时区毫无关系,因为timestamp一旦确定,其UTC时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以timestamp表示的,因为全球各地的计算机在任意时刻的timestamp都是完全相同的(假定时间已校准)。
把一个datetime类型转换为timestamp只需要简单调用timestamp()方法:
>>> from datetime import datetime
>>> dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
>>> dt.timestamp() # 把datetime转换为timestamp
1429417200.0
注意Python的timestamp是一个浮点数,整数位表示秒。
某些编程语言(如Java和JavaScript)的timestamp使用整数表示毫秒数,这种情况下只需要把timestamp除以1000就得到Python的浮点表示方法。
timestamp转换为datetime
要把timestamp转换为datetime,使用datetime提供的fromtimestamp()方法:
>>> from datetime import datetime
>>> t = 1429417200.0
>>> print(datetime.fromtimestamp(t))
2015-04-19 12:20:00
注意到timestamp是一个浮点数,它没有时区的概念,而datetime是有时区的。上述转换是在timestamp和本地时间做转换。
本地时间是指当前操作系统设定的时区。例如北京时区是东8区,则本地时间:
2015-04-19 12:20:00
实际上就是UTC+8:00时区的时间:
2015-04-19 12:20:00 UTC+8:00
而此刻的格林威治标准时间与北京时间差了8小时,也就是UTC+0:00时区的时间应该是:
2015-04-19 04:20:00 UTC+0:00
timestamp也可以直接被转换到UTC标准时区的时间:
>>> from datetime import datetime
>>> t = 1429417200.0
>>> print(datetime.fromtimestamp(t)) # 本地时间
2015-04-19 12:20:00
>>> print(datetime.utcfromtimestamp(t)) # UTC时间
2015-04-19 04:20:00
str转换为datetime
很多时候,用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
>>> from datetime import datetime
>>> cday = datetime.strptime('2015-6-1 18:19:59', '%Y-%m-%d %H:%M:%S')
>>> print(cday)
2015-06-01 18:19:59
字符串'%Y-%m-%d %H:%M:%S'规定了日期和时间部分的格式。
注意转换后的datetime是没有时区信息的。
datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:
>>> from datetime import datetime
>>> now = datetime.now()
>>> print(now.strftime('%a, %b %d %H:%M'))
Mon, May 05 16:28
datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
>>> from datetime import datetime, timedelta
>>> now = datetime.now()
>>> now
datetime.datetime(2015, 5, 18, 16, 57, 3, 540997)
>>> now + timedelta(hours=10)
datetime.datetime(2015, 5, 19, 2, 57, 3, 540997)
>>> now - timedelta(days=1)
datetime.datetime(2015, 5, 17, 16, 57, 3, 540997)
>>> now + timedelta(days=2, hours=12)
datetime.datetime(2015, 5, 21, 4, 57, 3, 540997)
可见,使用timedelta你可以很容易地算出前几天和后几天的时刻。
本地时间转换为UTC时间
本地时间是指系统设定时区的时间,例如北京时间是UTC+8:00时区的时间,而UTC时间指UTC+0:00时区的时间。
一个datetime类型有一个时区属性tzinfo,但是默认为None,所以无法区分这个datetime到底是哪个时区,除非强行给datetime设置一个时区:
>>> from datetime import datetime, timedelta, timezone
>>> tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00
>>> now = datetime.now()
>>> now
datetime.datetime(2015, 5, 18, 17, 2, 10, 871012)
>>> dt = now.replace(tzinfo=tz_utc_8) # 强制设置为UTC+8:00
>>> dt
datetime.datetime(2015, 5, 18, 17, 2, 10, 871012, tzinfo=datetime.timezone(datetime.timedelta(0, 28800)))
如果系统时区恰好是UTC+8:00,那么上述代码就是正确的,否则,不能强制设置为UTC+8:00时区。
时区转换
我们可以先通过utcnow()拿到当前的UTC时间,再转换为任意时区的时间:
# 拿到UTC时间,并强制设置时区为UTC+0:00:
>>> utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc)
>>> print(utc_dt)
2015-05-18 09:05:12.377316+00:00
# astimezone()将转换时区为北京时间:
>>> bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8)))
>>> print(bj_dt)
2015-05-18 17:05:12.377316+08:00
# astimezone()将转换时区为东京时间:
>>> tokyo_dt = utc_dt.astimezone(timezone(timedelta(hours=9)))
>>> print(tokyo_dt)
2015-05-18 18:05:12.377316+09:00
# astimezone()将bj_dt转换时区为东京时间:
>>> tokyo_dt2 = bj_dt.astimezone(timezone(timedelta(hours=9)))
>>> print(tokyo_dt2)
2015-05-18 18:05:12.377316+09:00
时区转换的关键在于,拿到一个datetime时,要获知其正确的时区,然后强制设置时区,作为基准时间。
利用带时区的datetime,通过astimezone()方法,可以转换到任意时区。
注:不是必须从UTC+0:00时区转换到其他时区,任何带时区的datetime都可以正确转换,例如上述bj_dt到tokyo_dt的转换。
小结
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。
如果要存储datetime,最佳方法是将其转换为timestamp再存储,因为timestamp的值与时区完全无关。
collections
- collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
定义一个class又小题大做了,这时,namedtuple就派上了用场:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
可以验证创建的Point对象是tuple的一种子类:
>>> isinstance(p, Point)
True
>>> isinstance(p, tuple)
True
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
# namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> list(od.keys()) # 按照插入的Key的顺序返回
['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print('remove:', last)
if containsKey:
del self[key]
print('set:', (key, value))
else:
print('add:', (key, value))
OrderedDict.__setitem__(self, key, value)
ChainMap
ChainMap可以把一组dict串起来并组成一个逻辑上的dict。ChainMap本身也是一个dict,但是查找的时候,会按照顺序在内部的dict依次查找。
什么时候使用ChainMap最合适?举个例子:应用程序往往都需要传入参数,参数可以通过命令行传入,可以通过环境变量传入,还可以有默认参数。我们可以用ChainMap实现参数的优先级查找,即先查命令行参数,如果没有传入,再查环境变量,如果没有,就使用默认参数。
下面的代码演示了如何查找user和color这两个参数:
from collections import ChainMap
import os, argparse
# 构造缺省参数:
defaults = {
'color': 'red',
'user': 'guest'
}
# 构造命令行参数:
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
namespace = parser.parse_args()
command_line_args = { k: v for k, v in vars(namespace).items() if v }
# 组合成ChainMap:
combined = ChainMap(command_line_args, os.environ, defaults)
# 打印参数:
print('color=%s' % combined['color'])
print('user=%s' % combined['user'])
没有任何参数时,打印出默认参数:
$ python3 use_chainmap.py
color=red
user=guest
当传入命令行参数时,优先使用命令行参数:
$ python3 use_chainmap.py -u bob
color=red
user=bob
同时传入命令行参数和环境变量,命令行参数的优先级较高:
$ user=admin color=green python3 use_chainmap.py -u bob
color=green
user=bob
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'programming':
... c[ch] = c[ch] + 1
...
>>> c
Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
>>> c.update('hello') # 也可以一次性update
>>> c
Counter({'r': 2, 'o': 2, 'g': 2, 'm': 2, 'l': 2, 'p': 1, 'a': 1, 'i': 1, 'n': 1, 'h': 1, 'e': 1})
Counter实际上也是dict的一个子类,上面的结果可以看出每个字符出现的次数。
base64
Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含64个字符的数组:
['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit:
这样我们得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
Python内置的base64可以直接进行base64的编解码:
>>> import base64
>>> base64.b64encode(b'binary\x00string')
b'YmluYXJ5AHN0cmluZw=='
>>> base64.b64decode(b'YmluYXJ5AHN0cmluZw==')
b'binary\x00string'
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种”url safe”的base64编码,其实就是把字符+和/分别变成-和_:
>>> base64.b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd++//'
>>> base64.urlsafe_b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd--__'
>>> base64.urlsafe_b64decode('abcd--__')
b'i\xb7\x1d\xfb\xef\xff'
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
Base64是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。
Base64适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:
# 标准Base64:
'abcd' -> 'YWJjZA=='
# 自动去掉=:
'abcd' -> 'YWJjZA'
去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
小结
Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
hashlib(摘要算法/哈希算法)
摘要算法简介
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
举个例子,你写了一篇文章,内容是一个字符串'how to use python hashlib - by Michael',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'。如果有人篡改了你的文章,并发表为'how to use python hashlib - by Bob',你可以一下子指出Bob篡改了你的文章,因为根据'how to use python hashlib - by Bob'计算出的摘要不同于原始文章的摘要。
可见,摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
MD5
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?'.encode('utf-8'))
print(md5.hexdigest())
计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in '.encode('utf-8'))
md5.update('python hashlib?'.encode('utf-8'))
print(md5.hexdigest())
试试改动一个字母,看看计算的结果是否完全不同。
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
SHA1
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in '.encode('utf-8'))
sha1.update('python hashlib?'.encode('utf-8'))
print(sha1.hexdigest())
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法不仅越慢,而且摘要长度更长。
有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要?完全有可能,因为任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。这种情况称为碰撞,比如Bob试图根据你的摘要反推出一篇文章'how to learn hashlib in python - by Bob',并且这篇文章的摘要恰好和你的文章完全一致,这种情况也并非不可能出现,但是非常非常困难。
摘要算法应用
摘要算法能应用到什么地方?举个常用例子:
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
| name | password |
|---|---|
| michael | 123456 |
| bob | abc999 |
| alice | alice2008 |
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。
正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
| username | password |
|---|---|
| michael | e10adc3949ba59abbe56e057f20f883e |
| bob | 878ef96e86145580c38c87f0410ad153 |
| alice | 99b1c2188db85afee403b1536010c2c9 |
当用户登录时,首先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明口令输入正确,如果不一致,口令肯定错误。
小结
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
hmac
通过哈希算法,我们可以验证一段数据是否有效,方法就是对比该数据的哈希值,例如,判断用户口令是否正确,我们用保存在数据库中的password_md5对比计算md5(password)的结果,如果一致,用户输入的口令就是正确的。
为了防止黑客通过彩虹表根据哈希值反推原始口令,在计算哈希的时候,不能仅针对原始输入计算,需要增加一个salt来使得相同的输入也能得到不同的哈希,这样,大大增加了黑客破解的难度。
如果salt是我们自己随机生成的,通常我们计算MD5时采用md5(message + salt)。但实际上,把salt看做一个“口令”,加salt的哈希就是:计算一段message的哈希时,根据不同口令计算出不同的哈希。要验证哈希值,必须同时提供正确的口令。
这实际上就是Hmac算法:Keyed-Hashing for Message Authentication。它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中。
和我们自定义的加salt算法不同,Hmac算法针对所有哈希算法都通用,无论是MD5还是SHA-1。采用Hmac替代我们自己的salt算法,可以使程序算法更标准化,也更安全。
Python自带的hmac模块实现了标准的Hmac算法。我们来看看如何使用hmac实现带key的哈希。
我们首先需要准备待计算的原始消息message,随机key,哈希算法,这里采用MD5,使用hmac的代码如下:
>>> import hmac
>>> message = b'Hello, world!' #转化成字节
>>> key = b'secret'
>>> h = hmac.new(key, message, digestmod='MD5')
>>> # 如果消息很长,可以多次调用h.update(msg)
>>> h.hexdigest()
'fa4ee7d173f2d97ee79022d1a7355bcf'
可见使用hmac和普通hash算法非常类似。hmac输出的长度和原始哈希算法的长度一致。需要注意传入的key和message都是bytes类型,str类型需要首先编码为bytes。
itertools
count()
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
首先,我们看看itertools提供的几个“无限”迭代器:
>>> import itertools
>>> natuals = itertools.count(1)
>>> for n in natuals:
... print(n)
...
1
2
3
...
因为count()会创建一个无限的迭代器,所以上述代码会打印出自然数序列,根本停不下来,只能按Ctrl+C退出。
cycle()
cycle()会把传入的一个序列无限重复下去:
>>> import itertools
>>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种
>>> for c in cs:
... print(c)
...
'A'
'B'
'C'
'A'
'B'
'C'
...
同样停不下来。
repeat()
repeat()负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数:
>>> ns = itertools.repeat('A', 3)
>>> for n in ns:
... print(n)
...
A
A
A
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。
takewhile()
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
itertools提供的几个迭代器操作函数更加有用:
chain()
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:
>>> for c in itertools.chain('ABC', 'XYZ'):
... print(c)
# 迭代效果:'A' 'B' 'C' 'X' 'Y' 'Z'
groupby()
groupby()把迭代器中相邻的重复元素挑出来放在一起:
>>> for key, group in itertools.groupby('AAABBBCCAAA'):
... print(key, list(group))
...
A ['A', 'A', 'A']
B ['B', 'B', 'B']
C ['C', 'C']
A ['A', 'A', 'A']
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。如果我们要忽略大小写分组,就可以让元素'A'和'a'都返回相同的key:
>>> for key, group in itertools.groupby('AaaBBbcCAAa', lambda c: c.upper()):
... print(key, list(group))
...
A ['A', 'a', 'a']
B ['B', 'B', 'b']
C ['c', 'C']
A ['A', 'A', 'a']
contextlib
try……finally
在Python中,读写文件这样的资源要特别注意,必须在使用完毕后正确关闭它们。正确关闭文件资源的一个方法是使用try...finally:
try:
f = open('/path/to/file', 'r')
f.read()
finally:
if f:
f.close()
with
写try...finally非常繁琐。Python的with语句允许我们非常方便地使用资源,而不必担心资源没有关闭,所以上面的代码可以简化为:
with open('/path/to/file', 'r') as f:
f.read()
并不是只有open()函数返回的fp对象才能使用with语句。实际上,任何对象,只要正确实现了上下文管理,就可以用于with语句。
实现上下文管理是通过__enter__和__exit__这两个方法实现的。例如,下面的class实现了这两个方法:
class Query(object):
def __init__(self, name):
self.name = name
def __enter__(self):
print('Begin')
return self
def __exit__(self, exc_type, exc_value, traceback):
if exc_type:
print('Error')
else:
print('End')
def query(self):
print('Query info about %s...' % self.name)
这样我们就可以把自己写的资源对象用于with语句:
with Query('Bob') as q:
q.query()
@contextmanager(+ yield)
编写__enter__和__exit__仍然很繁琐,因此Python的标准库contextlib提供了更简单的写法,上面的代码可以改写如下:
from contextlib import contextmanager
class Query(object):
def __init__(self, name):
self.name = name
def query(self):
print('Query info about %s...' % self.name)
@contextmanager
def create_query(name):
print('Begin')
q = Query(name)
yield q
print('End')
@contextmanager这个decorator接受一个generator,用yield语句把with ... as var把变量输出出去,然后,with语句就可以正常地工作了:
with create_query('Bob') as q:
q.query()
很多时候,我们希望在某段代码执行前后自动执行特定代码,也可以用@contextmanager实现。例如:
@contextmanager
def tag(name):
print("<%s>" % name)
yield
print("</%s>" % name)
with tag("h1"):
print("hello")
print("world")
上述代码执行结果为:
<h1>
hello
world
</h1>
代码的执行顺序是:
with语句首先执行yield之前的语句,因此打印出<h1>;yield调用会执行with语句内部的所有语句,因此打印出hello和world;- 最后执行
yield之后的语句,打印出</h1>。
因此,@contextmanager让我们通过编写generator来简化上下文管理。
@closing
如果一个对象没有实现上下文,我们就不能把它用于with语句。这个时候,可以用closing()来把该对象变为上下文对象。例如,用with语句使用urlopen():
from contextlib import closing
from urllib.request import urlopen
with closing(urlopen('https://www.python.org')) as page:
for line in page:
print(line)
closing也是一个经过@contextmanager装饰的generator,这个generator编写起来其实非常简单:
@contextmanager
def closing(thing):
try:
yield thing
finally:
thing.close()
它的作用就是把任意对象变为上下文对象,并支持with语句。
@contextlib还有一些其他decorator,便于我们编写更简洁的代码。
urllib
urllib提供了一系列用于操作URL的功能。
Get
urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
例如,对豆瓣的一个URLhttps://api.douban.com/v2/book/2129650进行抓取,并返回响应:
from urllib import request
with request.urlopen('https://api.douban.com/v2/book/2129650') as f:
data = f.read()
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', data.decode('utf-8'))
可以看到HTTP响应的头和JSON数据:
Status: 200 OK
Server: nginx
Date: Tue, 26 May 2015 10:02:27 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 2049
Connection: close
Expires: Sun, 1 Jan 2006 01:00:00 GMT
Pragma: no-cache
Cache-Control: must-revalidate, no-cache, private
X-DAE-Node: pidl1
Data: {"rating":{"max":10,"numRaters":16,"average":"7.4","min":0},"subtitle":"","author":["廖雪峰编著"],"pubdate":"2007-6",...}
如果我们要想模拟浏览器发送GET请求,就需要使用Request对象,通过往Request对象添加HTTP头,我们就可以把请求伪装成浏览器。例如,模拟iPhone 6去请求豆瓣首页:
from urllib import request
req = request.Request('http://www.douban.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))
这样豆瓣会返回适合iPhone的移动版网页:
...
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0">
<meta name="format-detection" content="telephone=no">
<link rel="apple-touch-icon" sizes="57x57" href="http://img4.douban.com/pics/cardkit/launcher/57.png" />
...
Post
如果要以POST发送一个请求,只需要把参数data以bytes形式传入。
我们模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
from urllib import request, parse
print('Login to weibo.cn...')
email = input('Email: ')
passwd = input('Password: ')
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))
如果登录成功,我们获得的响应如下:
Status: 200 OK
Server: nginx/1.2.0
...
Set-Cookie: SSOLoginState=1432620126; path=/; domain=weibo.cn
...
Data: {"retcode":20000000,"msg":"","data":{...,"uid":"1658384301"}}
如果登录失败,我们获得的响应如下:
...
Data: {"retcode":50011015,"msg":"\u7528\u6237\u540d\u6216\u5bc6\u7801\u9519\u8bef","data":{"username":"example@python.org","errline":536}}
Handler
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,我们需要利用ProxyHandler来处理,示例代码如下:
proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
with opener.open('http://www.example.com/login.html') as f:
pass
小结
urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏览器发出的请求,再根据浏览器的请求头来伪装,User-Agent头就是用来标识浏览器的。
常用第三方模块
Pillow
PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用。
由于PIL仅支持到Python 2.7,加上年久失修,于是一群志愿者在PIL的基础上创建了兼容的版本,名字叫Pillow,支持最新Python 3.x,又加入了许多新特性,因此,我们可以直接安装使用Pillow。
操作图像
来看看最常见的图像缩放操作,只需三四行代码:
from PIL import Image
# 打开一个jpg图像文件,注意是当前路径:
im = Image.open('test.jpg')
# 获得图像尺寸:
w, h = im.size
print('Original image size: %sx%s' % (w, h))
# 缩放到50%:
im.thumbnail((w//2, h//2))
print('Resize image to: %sx%s' % (w//2, h//2))
# 把缩放后的图像用jpeg格式保存:
im.save('thumbnail.jpg', 'jpeg')
其他功能如切片、旋转、滤镜、输出文字、调色板等一应俱全。
比如,模糊效果也只需几行代码:
from PIL import Image, ImageFilter
# 打开一个jpg图像文件,注意是当前路径:
im = Image.open('test.jpg')
# 应用模糊滤镜:
im2 = im.filter(ImageFilter.BLUR)
im2.save('blur.jpg', 'jpeg')
绘图生成字母验证码
PIL的ImageDraw提供了一系列绘图方法,让我们可以直接绘图。比如要生成字母验证码图片:
from PIL import Image, ImageDraw, ImageFont, ImageFilter
import random
# 随机字母:
def rndChar():
return chr(random.randint(65, 90))
# 随机颜色1:
def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))
# 随机颜色2:
def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))
# 240 x 60:
width = 60 * 4
height = 60
image = Image.new('RGB', (width, height), (255, 255, 255))
# 创建Font对象:
font = ImageFont.truetype('Arial.ttf', 36)
# 创建Draw对象:
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save('code.jpg', 'jpeg')
我们用随机颜色填充背景,再画上文字,最后对图像进行模糊,得到验证码图片如下:
requests
要通过GET访问一个页面,只需要几行代码:
>>> import requests
>>> r = requests.get('https://www.douban.com/') # 豆瓣首页
>>> r.status_code
200
>>> r.text
r.text
'<!DOCTYPE HTML>\n<html>\n<head>\n<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和...'
对于带参数的URL,传入一个dict作为params参数:
>>> r = requests.get('https://www.douban.com/search', params={'q': 'python', 'cat': '1001'})
>>> r.url # 实际请求的URL
'https://www.douban.com/search?q=python&cat=1001'
requests自动检测编码,可以使用encoding属性查看:
>>> r.encoding
'utf-8'
无论响应是文本还是二进制内容,我们都可以用content属性获得bytes对象:
>>> r.content
b'<!DOCTYPE html>\n<html>\n<head>\n<meta http-equiv="Content-Type" content="text/html; charset=utf-8">\n...'
requests的方便之处还在于,对于特定类型的响应,例如JSON,可以直接获取:
>>> r = requests.get('https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20weather.forecast%20where%20woeid%20%3D%202151330&format=json')
>>> r.json()
{'query': {'count': 1, 'created': '2017-11-17T07:14:12Z', ...
需要传入HTTP Header时,我们传入一个dict作为headers参数:
>>> r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'})
>>> r.text
'<!DOCTYPE html>\n<html>\n<head>\n<meta charset="UTF-8">\n <title>豆瓣(手机版)</title>...'
要发送POST请求,只需要把get()方法变成post(),然后传入data参数作为POST请求的数据:
>>> r = requests.post('https://accounts.douban.com/login', data={'form_email': 'abc@example.com', 'form_password': '123456'})
requests默认使用application/x-www-form-urlencoded对POST数据编码。如果要传递JSON数据,可以直接传入json参数:
params = {'key': 'value'}
r = requests.post(url, json=params) # 内部自动序列化为JSON
类似的,上传文件需要更复杂的编码格式,但是requests把它简化成files参数:
>>> upload_files = {'file': open('report.xls', 'rb')}
>>> r = requests.post(url, files=upload_files)
在读取文件时,注意务必使用'rb'即二进制模式读取,这样获取的bytes长度才是文件的长度。
把post()方法替换为put(),delete()等,就可以以PUT或DELETE方式请求资源。
除了能轻松获取响应内容外,requests对获取HTTP响应的其他信息也非常简单。例如,获取响应头:
>>> r.headers
{Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Content-Encoding': 'gzip', ...}
>>> r.headers['Content-Type']
'text/html; charset=utf-8'
requests对Cookie做了特殊处理,使得我们不必解析Cookie就可以轻松获取指定的Cookie:
>>> r.cookies['ts']
'example_cookie_12345'
要在请求中传入Cookie,只需准备一个dict传入cookies参数:
>>> cs = {'token': '12345', 'status': 'working'}
>>> r = requests.get(url, cookies=cs)
最后,要指定超时,传入以秒为单位的timeout参数:
>>> r = requests.get(url, timeout=2.5) # 2.5秒后超时
chardet
字符串编码一直是令人非常头疼的问题,尤其是我们在处理一些不规范的第三方网页的时候。虽然Python提供了Unicode表示的str和bytes两种数据类型,并且可以通过encode()和decode()方法转换,但是,在不知道编码的情况下,对bytes做decode()不好做。
对于未知编码的bytes,要把它转换成str,需要先“猜测”编码。猜测的方式是先收集各种编码的特征字符,根据特征字符判断,就能有很大概率“猜对”。
当然,我们肯定不能从头自己写这个检测编码的功能,这样做费时费力。chardet这个第三方库正好就派上了用场。用它来检测编码,简单易用。
使用chardet
当我们拿到一个bytes时,就可以对其检测编码。用chardet检测编码,只需要一行代码:
>>> chardet.detect(b'Hello, world!')
{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
检测出的编码是ascii,注意到还有个confidence字段,表示检测的概率是1.0(即100%)。
我们来试试检测GBK编码的中文:
>>> data = '离离原上草,一岁一枯荣'.encode('gbk')
>>> chardet.detect(data)
{'encoding': 'GB2312', 'confidence': 0.7407407407407407, 'language': 'Chinese'}
检测的编码是GB2312,注意到GBK是GB2312的超集,两者是同一种编码,检测正确的概率是74%,language字段指出的语言是'Chinese'。
对UTF-8编码进行检测:
>>> data = '离离原上草,一岁一枯荣'.encode('utf-8')
>>> chardet.detect(data)
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
我们再试试对日文进行检测:
>>> data = '最新の主要ニュース'.encode('euc-jp')
>>>用Python来编写脚本简化日常的运维工作是Python的一个重要用途。在Linux下,有许多系统命令可以让我们时刻监控系统运行的状态,如ps,top,free等等。要获取这些系统信息,Python可以通过subprocess模块调用并获取结果。但这样做显得很麻烦,尤其是要写很多解析代码。
在Python中获取系统信息的另一个好办法是使用psutil这个第三方模块。顾名思义,psutil = process and system utilities,它不仅可以通过一两行代码实现系统监控,还可以跨平台使用,支持Linux/UNIX/OSX/Windows等,是系统管理员和运维小伙伴不可或缺的必备模块。 chardet.detect(data)
{'encoding': 'EUC-JP', 'confidence': 0.99, 'language': 'Japanese'}
可见,用chardet检测编码,使用简单。获取到编码后,再转换为str,就可以方便后续处理。
psutil
用Python来编写脚本简化日常的运维工作是Python的一个重要用途。在Linux下,有许多系统命令可以让我们时刻监控系统运行的状态,如ps,top,free等等。要获取这些系统信息,Python可以通过subprocess模块调用并获取结果。但这样做显得很麻烦,尤其是要写很多解析代码。
在Python中获取系统信息的另一个好办法是使用psutil这个第三方模块。顾名思义,psutil = process and system utilities,它不仅可以通过一两行代码实现系统监控,还可以跨平台使用,支持Linux/UNIX/OSX/Windows等,是系统管理员和运维小伙伴不可或缺的必备模块。
类特殊成员(属性和方法)
@classmethod:
定义操作类,而不是操作实例的方法。classmethod改变了调用方法的方式,因此类方法的第一个参数是类本身,而不是实例。@classmethod最常见的用途是定义备选构造方法。
1.定义方式
Python中3种方式定义类方法, 常规方式, @classmethod修饰方式, @staticmethod修饰方式
- 普通的self类方法foo()需要通过self参数隐式的传递当前类对象的实例;
- @classmethod修饰的方法class_foo()需要通过cls参数传递当前类对象;
- @staticmethod修饰的方法定义与普通函数是一样的。
self和cls的区别不是强制的,只是PEP8中一种编程风格,self通常用作实例方法的第一参数,cls通常用作类方法的第一参数。即通常用self来传递当前类对象的实例,cls传递当前类对象。
2. @classmethod 特点
- 声明一个类方法
- 第一个参数必须是
cls, 它可以访问类的属性 - 类的方法只能访问类的属性,不能访问实例属性
- 类的方法可以通过
ClassName.MethodName()访问也可以通过实例来访问。 - 它可以返回一个类的实例
例子:
class Student:
name = 'unknown' # class attribute
def __init__(self):
self.age = 20 # instance attribute
@classmethod
def tostring(cls):
print('Student Class Attributes: name=',cls.name)
类方法访问实例属性时,会报错
class Student:
name = 'unknown' # class attribute
def __init__(self):
self.age = 20 # instance attribute
@classmethod
def tostring(cls):
print('Student Class Attributes: name=',cls.name,', age=', cls.age)
>>> Student.tostring()
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
Student.tostring()
File "<pyshell#21>", line 7, in display
print('Student Class Attributes: name=',cls.name,', age=', cls.age)
AttributeError: type object 'Student' has no attribute 'age'
例子
from datetime import date
# random Person
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
@staticmethod
def fromFathersAge(name, fatherAge, fatherPersonAgeDiff):
return Person(name, date.today().year - fatherAge + fatherPersonAgeDiff)
@classmethod
def fromBirthYear(cls, name, birthYear):
return cls(name, date.today().year - birthYear)
def display(self):
print(self.name + "'s age is: " + str(self.age))
class Man(Person):
sex = 'Male'
man = Man.fromBirthYear('John', 1985)
print(isinstance(man, Man))
man1 = Man.fromFathersAge('John', 1965, 20)
print(isinstance(man1, Man))
3. @classmethod 和 @staticmethod
| @classmethod | @staticmethod |
|---|---|
| 声明一个类的方法 | 声明一个静态方法 |
| 可以访问类的属性,不可以访问实例属性 | 既不可以访问类属性,也不可以访问实例属性 |
可以使用 ClassName.MethodName() 调用或者 object.MethodName().调用 |
可以使用 ClassName.MethodName() 调用后者object.MethodName().调用 |
| 可以声明一个类的工厂方法,返回一个实例 | 不可以返回一个实例 |
第 2 个解释
使用官方的说法:
classmethod(function)
中文说明:
classmethod是用来指定一个类的方法为类方法,没有此参数指定的类的方法为实例方法,使用方法如下:
class C:
@classmethod
def f(cls, arg1, arg2, ...): ...
看后之后真是一头雾水。说的啥子东西呢???
自己到国外的论坛看其他的例子和解释,顿时就很明朗。 下面自己用例子来说明。
看下面的定义的一个时间类:
class Data_test(object):
day=0
month=0
year=0
def __init__(self,year=0,month=0,day=0):
self.day=day
self.month=month
self.year=year
def out_date(self):
print "year :"
print self.year
print "month :"
print self.month
print "day :"
print self.day
t=Data_test(2016,8,1)
t.out_date()
输出:
year :
2016
month :
8
day :
1
符合期望。
如果用户输入的是 “2016-8-1” 这样的字符格式,那么就需要调用Date_test 类前做一下处理:
string_date='2016-8-1'
year,month,day=map(int,string_date.split('-'))
s=Data_test(year,month,day)
先把‘2016-8-1’ 分解成 year,month,day 三个变量,然后转成int,再调用Date_test(year,month,day)函数。 也很符合期望。
那我可不可以把这个字符串处理的函数放到 Date_test 类当中呢?
那么@classmethod 就开始出场了
class Data_test2(object):
day=0
month=0
year=0
def __init__(self,year=0,month=0,day=0):
self.day=day
self.month=month
self.year=year
@classmethod
def get_date(cls, string_date):
#这里第一个参数是cls, 表示调用当前的类名
year,month,day=map(int,string_date.split('-'))
date1=cls(year,month,day)
#返回的是一个初始化后的类
return date1
def out_date(self):
print "year :"
print self.year
print "month :"
print self.month
print "day :"
print self.day
在Date_test类里面创建一个成员函数, 前面用了@classmethod装饰。 它的作用就是有点像静态类,比静态类不一样的就是它可以传进来一个当前类作为第一个参数。
那么如何调用呢?
r=Data_test2.get_date("2016-8-1")
r.out_date()
输出:
year :
2016
month :
8
day :
1
这样子等于先调用get_date()对字符串进行处理,然后才使用Data_test的构造函数初始化。
这样的好处就是你以后重构类的时候不必要修改构造函数,只需要额外添加你要处理的函数,然后使用装饰符 @classmethod 就可以了。
补充:
以上,@classmethod的使用方法已经说的非常清楚了,但是其实细看的话还是感觉像是缺了一点什么,对的,@classmethod的使用场景上文最后一句的“好处是以后在重构类的时候不需要修改构造函数,只要额外添加你要处理的函数,然后使用@classmethod即可”。
好的,解释一下用法,在已写好初始类的情况下,想给初始类再新添功能,不需要改初始类,只要在下一个类内部新写一个方法,方法用@classmethod装饰一下即可。
所以上面的例子应该修改一下:
# 初始类:
class Data_test(object):
day=0
month=0
year=0
def __init__(self,year=0,month=0,day=0):
self.day=day
self.month=month
self.year=year
def out_date(self):
print "year :"
print self.year
print "month :"
print self.month
print "day :"
print self.day
# 新增功能:
class Str2IntParam(Data_test):
@classmethod
def get_date(cls, string_date):
#这里第一个参数是cls, 表示调用当前的类名
year,month,day=map(int,string_date.split('-'))
date1=cls(year,month,day)
#返回的是一个初始化后的类
return date1
# 使用:
r = Str2IntParam.get_date("2016-8-1")
r.out_date()
# 输出:
year :
2016
month :
8
day :
1
新增的功能get_date,初始类Data_test不需要改变,在Str2IntParam类里面修改就好了,Str2IntParam继承Data_test。
@classmethod,@staticmethod,@property三种装饰器
@classmethod
类方法,不需要实例化,也不需要self参数,需要一个cls参数,可以用类名调用,也可以用对象来调用。
原则上,类方法是将类本身作为对象进行操作的方法。假设有个方法,且这个方法在逻辑上采用类本身作为对象来调用更合理,那么这个方法就可以定义为类方法
@staticmethod
静态方法,不需要实例化,不需要self和cls等参数,就跟使用普通的函数一样,只是封装在类中
静态方法是类中的函数,不需要实例。静态方法主要是用来存放逻辑性的代码,逻辑上属于类,但是和类本身没有关系,也就是说在静态方法中,不会涉及到类中的属性和方法的操作。可以理解为,静态方法是个独立的、单纯的函数,它仅仅托管于某个类的名称空间中,便于使用和维护。
类方法和静态方法的使用:
class Foo(object):
@classmethod
def cls_fun(cls):
return "hello world"
@staticmethod
def static_fun():
return "hello python"
foo = Foo()
print(Foo.cls_fun())
print(foo.cls_fun())
print(Foo.static_fun())
注意点: 使用@staticmethod或@classmethod,就可以不需要实例化,直接类名.方法名()来调用。 如果在@staticmethod中要调用到这个类的一些属性方法,只能直接类名.属性名或类名.方法名 @classmethod因为持有cls参数,可以来调用类的属性,类的方法,实例化对象等,避免硬编码。
@property
属性方法,主要作用是将一个操作方法封装成一个属性,用户用起来就和操作普通属性完全一致,非常简单.定义时,在实例方法的基础上添加@property装饰器,并且只有一个self参数,调用时,不需要括号
@property 是经典类中的一种装饰器,新式类中具有三种: 1.@property获取属性 2.@方法名.setter 修改属性 3.@方法名.deleter 删除属性
@property的使用:
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
@property
def price(self):
# 实际价格 = 原价*折扣
new_price = self.original_price*self.discount
return new_price
@price.setter
def price(self,value):
self.original_price = value
@price.deleter
def price(self):
del self.original_price
obj = Goods()
print(obj.price)
obj.price = 200
print(obj.price)
del obj.price # 删除了类中的price属性若再次调用就会报错
总结:类方法,是直接对类操作时候定义的,实例化方法是操作实例化对象时候定义的,静态方法与类无关,就是独立的逻辑单元。@property是将方法转为属性,直接可使用其返回值,提供了可读可写可删除的操作,如果像只读效果,就只需要定义@property就可以,不定义代表禁止其他操作。
————————————————
版权声明:本文为CSDN博主「他们叫我浪浪」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43613053/article/details/84979916
Python setattr()、getattr()、hasattr()函数用法详解
Python hasattr()函数
hasattr() 函数用来判断某个类实例对象是否包含指定名称的属性或方法。该函数的语法格式如下:
hasattr(obj, name)
其中 obj 指的是某个类的实例对象,name 表示指定的属性名或方法名。同时,该函数会将判断的结果(True 或者 False)作为返回值反馈回来。
举个例子:
class CLanguage:
def __init__ (self):
self.name = "C语言中文网"
self.add = "http://c.biancheng.net"
def say(self):
print("我正在学Python")
clangs = CLanguage()
print(hasattr(clangs,"name"))
print(hasattr(clangs,"add"))
print(hasattr(clangs,"say"))
程序输出结果为: True True True
显然,无论是属性名还是方法名,都在 hasattr() 函数的匹配范围内。因此,我们只能通过该函数判断实例对象是否包含该名称的属性或方法,但不能精确判断,该名称代表的是属性还是方法。
Python getattr() 函数
getattr() 函数获取某个类实例对象中指定属性的值。没错,和 hasattr() 函数不同,该函数只会从类对象包含的所有属性中进行查找。
getattr() 函数的语法格式如下:
getattr(obj, name[, default])
其中,obj 表示指定的类实例对象,name 表示指定的属性名,而 default 是可选参数,用于设定该函数的默认返回值,即当函数查找失败时,如果不指定 default 参数,则程序将直接报 AttributeError 错误,反之该函数将返回 default 指定的值。
举个例子:
class CLanguage:
def __init__ (self):
self.name = "C语言中文网"
self.add = "http://c.biancheng.net"
def say(self):
print("我正在学Python")
clangs=CLanguage()
print(getattr(clangs,"name"))
print(getattr(clangs,"add"))
print(getattr(clangs,"say"))
print(getattr(clangs,"display",'nodisplay'))
程序执行结果为:
C语言中文网
http://c.biancheng.net
<bound method CLanguage.say of <__main__.CLanguage object at 0x000001FC2F2E3198>>
nodisplay
可以看到,对于类中已有的属性,getattr() 会返回它们的值,而如果该名称为方法名,则返回该方法的状态信息;反之,如果该明白不为类对象所有,要么返回默认的参数,要么程序报 AttributeError 错误。
Python setattr()函数
setattr() 函数的功能相对比较复杂,它最基础的功能是修改类实例对象中的属性值。其次,它还可以实现为实例对象动态添加属性或者方法。
setattr() 函数的语法格式如下:
setattr(obj, name, value)
首先,下面例子演示如何通过该函数修改某个类实例对象的属性值:
class CLanguage: def __init__ (self): self.name = "C语言中文网" self.add = "http://c.biancheng.net" def say(self): print("我正在学Python")clangs = CLanguage()print(clangs.name)print(clangs.add)setattr(clangs,"name","Python教程")setattr(clangs,"add","http://c.biancheng.net/python")print(clangs.name)print(clangs.add)
程序运行结果为:
C语言中文网 http://c.biancheng.net Python教程 http://c.biancheng.net/python
甚至利用 setattr() 函数,还可以将类属性修改为一个类方法,同样也可以将类方法修改成一个类属性。例如:
class CLanguage:
def __init__ (self):
self.name = "C语言中文网"
self.add = "http://c.biancheng.net"
def say(self):
print("我正在学Python")
clangs = CLanguage()
print(clangs.name)
print(clangs.add)
setattr(clangs,"name","Python教程")
setattr(clangs,"add","http://c.biancheng.net/python")
print(clangs.name)
print(clangs.add)
程序运行结果为:
C语言中文网 http://c.biancheng.net 我正在学Python
显然,通过修改 name 属性的值为 say(这是一个外部定义的函数),原来的 name 属性就变成了一个 name() 方法。
使用 setattr() 函数对实例对象中执行名称的属性或方法进行修改时,如果该名称查找失败,Python 解释器不会报错,而是会给该实例对象动态添加一个指定名称的属性或方法。例如:
def say(self):
print("我正在学Python")
class CLanguage:
def __init__ (self):
self.name = "C语言中文网"
self.add = "http://c.biancheng.net"
clangs = CLanguage()
print(clangs.name)
print(clangs.add)
setattr(clangs,"name",say)
clangs.name(clangs)
程序执行结果为:
C语言中文网 我正在学Python
可以看到,虽然 CLanguage 为空类,但通过 setattr() 函数,我们为 clangs 对象动态添加了一个 name 属性和一个 say() 方法。
访问数据库
使用SQLAlchemy
数据库表是一个二维表,包含多行多列。把一个表的内容用Python的数据结构表示出来的话,可以用一个list表示多行,list的每一个元素是tuple,表示一行记录,比如,包含id和name的user表:
[
('1', 'Michael'),
('2', 'Bob'),
('3', 'Adam')
]
Python的DB-API返回的数据结构就是像上面这样表示的。
但是用tuple表示一行很难看出表的结构。如果把一个tuple用class实例来表示,就可以更容易地看出表的结构来:
class User(object):
def __init__(self, id, name):
self.id = id
self.name = name
[
User('1', 'Michael'),
User('2', 'Bob'),
User('3', 'Adam')
]
这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?
但是由谁来做这个转换呢?所以ORM框架应运而生。
在Python中,最有名的ORM框架是SQLAlchemy。我们来看看SQLAlchemy的用法。
首先通过pip安装SQLAlchemy:
$ pip install sqlalchemy
然后,利用上次我们在MySQL的test数据库中创建的user表,用SQLAlchemy来试试:
第一步,导入SQLAlchemy,并初始化DBSession:
# 导入:
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建对象的基类:
Base = declarative_base()
# 定义User对象:
class User(Base):
# 表的名字:
__tablename__ = 'user'
# 表的结构:
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 初始化数据库连接:
engine = create_engine('mysql+mysqlconnector://root:password@localhost:3306/test')
# 创建DBSession类型:
DBSession = sessionmaker(bind=engine)
以上代码完成SQLAlchemy的初始化和具体每个表的class定义。如果有多个表,就继续定义其他class,例如School:
class School(Base):
__tablename__ = 'school'
id = ...
name = ...
create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
你只需要根据需要替换掉用户名、口令等信息即可。
下面,我们看看如何向数据库表中添加一行记录。
由于有了ORM,我们向数据库表中添加一行记录,可以视为添加一个User对象:
# 创建session对象:
session = DBSession()
# 创建新User对象:
new_user = User(id='5', name='Bob')
# 添加到session:
session.add(new_user)
# 提交即保存到数据库:
session.commit()
# 关闭session:
session.close()
可见,关键是获取session,然后把对象添加到session,最后提交并关闭。DBSession对象可视为当前数据库连接。
如何从数据库表中查询数据呢?有了ORM,查询出来的可以不再是tuple,而是User对象。SQLAlchemy提供的查询接口如下:
# 创建Session:
session = DBSession()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
user = session.query(User).filter(User.id=='5').one()
# 打印类型和对象的name属性:
print('type:', type(user))
print('name:', user.name)
# 关闭Session:
session.close()
运行结果如下:
type: <class '__main__.User'>
name: Bob
可见,ORM就是把数据库表的行与相应的对象建立关联,互相转换。
由于关系数据库的多个表还可以用外键实现一对多、多对多等关联,相应地,ORM框架也可以提供两个对象之间的一对多、多对多等功能。
例如,如果一个User拥有多个Book,就可以定义一对多关系如下:
class User(Base):
__tablename__ = 'user'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 一对多:
books = relationship('Book')
class Book(Base):
__tablename__ = 'book'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# “多”的一方的book表是通过外键关联到user表的:
user_id = Column(String(20), ForeignKey('user.id'))
当我们查询一个User对象时,该对象的books属性将返回一个包含若干个Book对象的list。
小结
ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换。
正确使用ORM的前提是了解关系数据库的原理。
sqlalchemy.sql.schema.Index
class sqlalchemy.schema.Index(name, *expressions, **kw)
表级索引。
定义复合(一列或多列)索引。
例如。::
sometable = Table("sometable", metadata,
Column("name", String(50)),
Column("address", String(100))
)
Index("some_index", sometable.c.name)
对于无虚饰,单列索引,添加 Column 也支持 ::index=True
sometable = Table("sometable", metadata,
Column("name", String(50), index=True)
)
对于复合索引,可以指定多个列::
Index("some_index", sometable.c.name, sometable.c.address)
也支持函数索引,通常使用 func 与表绑定一起构造 Column 物体::
Index("some_index", func.lower(sometable.c.name))
安 Index 也可以手动与 Table ,通过内联声明或使用 Table.append_constraint() . 使用此方法时,可以将索引列的名称指定为字符串::
Table("sometable", metadata,
Column("name", String(50)),
Column("address", String(100)),
Index("some_index", "name", "address")
)
要支持此表单中的函数索引或基于表达式的索引,请 text() 可使用构造:
from sqlalchemy import text
Table("sometable", metadata,
Column("name", String(50)),
Column("address", String(100)),
Index("some_index", text("lower(name)"))
)
一、变量和简单数据类型
- name.title()
- 输出name字符串,且令首字母大写输出
- name.upper()
- 输出name字符串,且全部字母大写输出
- name.lower()
- 输出name字符串,且全部字母小写输出
- name.rstrip()
- 输出name字符串,且字符串末尾去掉多余的空白
- 在输出字符串拼接中,如果涉及int或者其他型,应该采用str()强转成字符串
- 除法如果只写整数如3/2,那么出来默认int型,为1,如果想要小数,需要在除数或者被除数中加入浮点类型
- python中输入:import this,出现python之禅(The zen of python)
二、列表
- 列表:在Python中,用方括号([] )来表示列表,并用逗号来分隔其中的元素。
- 列表中,第一个是arr[0],最后一个是arr[-1]
- 可以修改列表中任意元素的值
- 列表插入元素
- arr.append(‘another’):在列表后添加元素
- 使用方法insert() 可在列表的任何位置添加新元素。为此,你需要指定新元素的索引和值。
- arr.insert(0,’another’)
- 列表删除元素
- del arr[0]
- 方法pop() 可删除列表末尾的元素,并让你能够接着使用它。术语弹出 (pop)源自这样的类比:列表就像一个栈,而删除列表末尾的元素相当于弹出栈顶元素。
- arr.pop():删除列表末尾的元素
- 实际上,你可以使用pop() 来删除列表中任何位置的元素,只需在括号中指定要删除的元素的索引即可。
- arr.pop(0)
- 别忘了,每当你使用pop() 时,被弹出的元素就不再在列表中了。
- 有时候,你不知道要从列表中删除的值所处的位置。如果你只知道要删除的元素的值,可使用方法remove() 。
- arr.remove(‘name’)
- 方法remove() 只删除第一个指定的值。如果要删除的值可能在列表中出现多次,就需要使用循环来判断是否删除了所有这样的值。
- 组织列表
- sort
- 方法sort() 永久性地修改了列表元素的排列顺序(默认为首字母排列顺序)。
- 你还可以按与字母顺序相反的顺序排列列表元素,为此,只需向sort() 方法传递参数reverse=True 。下面的示例将汽车列表按与字母顺序相反的顺序排列:
- sort(reverse = True)反序
- sorted
- 要保留列表元素原来的排列顺序,同时以特定的顺序呈现它们,可使用函数sorted() 。函数sorted() 让你能够按特定顺序显示列表元素,同时不影响它们在列表中的原始排 列顺序。
- sort